Introduction
Cockroach (CR) allergies have been recognized as an
important cuase of imunoglobulin E (IgE)-mediated type I
hypersensitivity since 1964 (1).
In a previous study, it was found that 44% of 755 allergic patients
who were treated at the allergy clinics in New York had positive
reactions to CR extract in the skin prick test (SPT), and 13% of
those subjects were allergic to CR alone (1). German CR (Blattella
germanica; Bla g), American CR [Periplaneta americana (P.
americana); Per a] and smoky brown CR (Periplaneta
fuliginosa) are the dominant indoor CR species which cause
allergies among populations worldwide (2). In China, a total of 25.7% of
patients with allergies are found to be positive for American CR
allergens and 18.7% are found to be positive for German CR
allergens by the SPT (3).
There are 22 IgE binding components in P.
americana, including the proteins of 23, 28, 35, 38, 40, 49,
72, 78 and 97 kDa as major allergens (4), but only a few of these allergens
namely, Per a 1 (5), Per a 2
(previousy known as Cr PI) (6),
Per a 3 (7), Per a 4 (8), Per a 5 (9), Per a 6 (10), Per a 7 (11), Per a 9 (previousy known as
Periplaneta americana arginine kinase) (12) and Per a 10 (13) have been characterized. Per a 9 is
an arginine kinase, purified from American CR extract by monoclonal
antibody based-affinity chromatography reacted with IgE in sera of
all CR allergic Thai patients (12). Attempts to isolate Per a 9 from
the American CR extract have been extremely laborious and have
resulted in low yields. To day, only 3 groups of researchers have
submitted these allergen genes (AY563004.1, GU301882.1 and
EU429466) in GenBank. The availability of the sequence makes it
possible to produce recombinant Per a 9 in large amounts to study
both its physiologic role and its implications in allergic
reactions.
CR immunotherapy is uncommonly used and reports on
its effectiveness are very limited (14,15). The elucidation of B and T cell
epitopes of allergens broaden our understanding of the
structure-function relationship and predict the basis of
cross-reactivity. The cross-reactive epitopes may be useful in
reducing the number of allergens without compromising the efficacy
of therapy (16). B cell epitopes
can be applied in the diagnosis, therapy and development of
effective vaccines for immunotherapy. They can be identified by a
number of methods, particularly computational tools, which provide
a promising and rapid alternative. The predicted B cell epitopes
may be modified to reduce the allergenicity of an allergen
(17). T cell epitopes have been
successfully identified based on computer simulation over the past
decade. Extracellular peptides have to bind to major
histocompatibility complex (MHC) class II to stimulate T lymphocyte
responses. Thus, T cell epitopes have been predicted indirectly by
the identification of MHC-binding molecules (18). In the present study, we firstly
cloned and expressed the American CR major allergen, Per a 9, and
subseqently identified the B and T cell epitopes of the Per a 9
allergen using an in silico approach. Our findings provide
evidence of their potential use in the development of peptide-based
vaccines for combating CR allergies.
Materials and methods
Ethics statement
The study protocol was approved by the Ethics
Committee of the First Affiliated Hospital of Nanjing Medical
University, Nanjing, China. Written informed consent for the use of
blood samples was obtained from all participants prior to study
entry according to the declaration of Helsinki.
Patients and samples
A total of 16 patients with allergic rhinitis with
positive SPT results (allergens were supplied by ALK-Abelló, Inc.,
Hørsholm, Denmark) and with positive serum IgE test results to
American CR extract [by using ImmunoCAP assay (Pharmacia
Diagnostics AB, Uppsala, Sweden)], and 6 healthy controls (HC) were
recruited in this study. Serum (4 ml) from peripheral venous blood
was collected from each patient and the healthy controls for
western blot analysis.
Cloning of cDNA encoding the full length
of Per a 9 gene
Total RNA was isolated from adult female CRs reared
at our institute using TRIzol reagent (Invitrogen, Carlsbad, CA,
USA). Total RNA was quantified by measuring the absorbance ratios
at 260/280 nm. cDNA was prepared by reverse transcriptase using a
commercial RNA-PCR kit according to the manufacturer's instructions
(Takara Biotech Co., Ltd., Dalian, China). For each reaction, 1
μg of total RNA was reverse transcribed using oligo-d(T).
cDNA encoding Per a 9 was amplified by PCR using primers based on
the no-coding sequence of the Per a 9 gene (AY563004.1; forward,
5′-TACA GCAAGTGGGACAGCAG-3′ and reverse, 5′-ATATGGGCAT
CAAAGATATA-3′). The PCR conditions were 95°C/5 min (1 cycle),
95°C/1 min, 55°C/1 min and 72°C/1 min (30 cycles), and 72°C/5 min
(1 cycle). The purified PCR product was cloned into the pMD18-T
vector (Takara Biotech Co., Ltd.), before being transformed into
Escherichia coli (E. coli) strain DH5α. The inserts
were sequenced on an ABI Prism 377 DNA sequencer (Applied
Biosystems, Foster City, CA, USA). DNA sequence data were
translated to amino acid sequence using the Show Translation tool
in the SMS software package (http://www.bioinformatics.org/SMS/).
Expression and purification of Per a 9 in
E. coli
The Per a 9 gene was subcloned into the pET15b
vector (Novagen, Madison, WI, USA) using the NdeI and
BamHI sites and verified by DNA sequencing. The recombinant
pET15b-Per a 9 plasmid was transformed into the ArcticExpress™
(DE3) RP host strain. A colony of the selected transformed
ArcticExpress™ (DE3) RP E. coli on an overnight
LB-ampicillin agar plate was inoculated into 5 ml of LB-ampicillin
broth, and incubated at 15, 25 or 37°C, respectively overnight. One
milliliter of the culture was inoculated into 50 ml of fresh
LB-ampicillin broth and incubated at 37°C with shaking at 250 rpm
until the optical density (OD) at A600nm reached
0.6. Subsequently, IPTG was added to a final concentration of 1 mM
and the culture was incubated for a further 4 h. The bacterial
cells were harvested by centrifugation at 4,000 × g at 4°C for 20
min, and were lysed in lysis buffer by sonication at 20 kHz, 2 min
pulse-on, 3 min pulse-off. Cell debris was removed by
centrifugation at 12,000 × g at 4°C for 20 min. The supernatant was
loaded on a Nickel column (Genscript, Nanjing, China), washed with
running buffer containing 50 mM Tris-HCl, 300 mM NaCl and 5%
glycerol (pH 8.0), and eluted with elution buffer containing 50 mM
Tris-HCl, 300 mM NaCl, 50 and 250 mM imidazole and 5% glycerol (pH
8.0). The eluted fractions washed with 250 mM imidazole were
obtained and identified as Per a 9.
Immunoreactivity of human sera with
recombinant Per a 9
A 96-well plate was coated with purified recombinant
Per a 9 at 10 μg/ml in carbonate-bicarbonate buffer (0.05 M,
pH 9.6) overnight at 4°C, 100 μl/well. Human serum samples
[1:20 dilution in phosphate-buffered saline (PBS)-Tween-20 with 2%
BSA] were then added to the plates for 2 h at room temperature.
Following IgE binding, the plates were incubated with horseradish
peroxidase-labeled goat anti-human IgE (1:2,500 dilution) (KPL,
Inc., Gaithersburg, MD, USA), and the color was developed with
tetramethylbenzidine peroxidase substrate. The plates were read on
a microplate reader (Eon; BioTek, Winooski, Vermont, USA) at an
absorbance of 405 nm. The cut-off of the enzyme-linked
immunosorbent assay (ELISA) was calculated as the mean of the
negative controls plus 2 standard deviations (SDs).
Western blot analysis of IgE
reactivity
Immunoblots for the detection of serum specific IgE
were performed using recombinant Per a 9 as previously described
(19,20). Recombinant Per a 9 (5 μg)
was added to a sodium dodecyl sulfate-polyacrylamide gel
electrophoresis (SDS-PAGE) (gel concentration of 15%) under
reducing conditions and then transferred onto nitrocellulose
membranes. The nitrocellulose membranes were incubated with the
sera of the patients with American CR allergies (1:5 to 1:20 in
PBS-Tween-20 with 1% BSA, 10% normal goat serum) for 90 min.
Following rinsing with PBS, the membranes were incubated with
peroxidase-labeled anti-human IgE monoclonal antibody. The positive
protein bands were visualized by incubating the membranes with
tetramethylbenzidine peroxidase substrate. Sera from 2 non-atopic
subjects were used as negative controls.
Basophil activation test
The expression of CD63 and CCR3 on the basophil
surface is considered as an indicator of basophil activation
(21,22). Briefly, peripheral blood
mononucleated cells (PBMCs) from 20 ml blood donated by 4 healthy
volunteers were separated by Ficoll-Paque density gradient, and
treated with 10 ml LS (a solution containing 1.3 M NaCl, 0.005 M
KCl and 0.01 lactic acid, pH 3.9) for 2 min at 8°C. Following
neutralization with 12% Tris (pH 10.9), non-specific IgE on the
basophils was stripped off and the cells were passively sensitized
with the sera of patients with American CR allergies or the healthy
controls (n=4, 1 in 10 dilution, 2 h at 37°C) (same patients and
controls as mentioned above) as previously described (22). The cells were then challenged with
Per a 9 (1.0 μg/ml) for 15 min at 37°C. A goat anti-human
IgE antibody (Serotec, Kidlington, UK) was used as a positive
control. CCR3-PE-labeled antibody (85-12-1939–42; eBioscience Inc.,
San Diego, CA, USA) and anti-human CD63-FITC antibody
(HH-MHCD63014; Invitrogen) were added to the cells for 15 min at
37°C. Flow cytometric analysis of surface markers was performed at
488 nm on a FACSAria flow cytometer (Becton-Dickinson, Franklin
Lakes, NJ, USA) and analyzed by FACSDiva software.
Sequence retrieval and phylogenetic
analysis
The complete amino acid sequence of the cloned Per a
9 gene was used as query to search for homologous sequences through
the Swiss-Prot/TrEMBL (Uniprot; http://www.uniprot.org/) and tBLASTn in NCBI
(blast.ncbi.nlm.nih.gov/Blast.cgi) (10,23–25). The phylogenetic tree was obtained
by using the maximum-likelihood (ML) method on the basis of the JTT
amino acid sequence distance implemented in MEGA 5.1, and the
reliability was evaluated by the bootstrap method with 1,000
replications (24–32).
Physiochemical analysis and
post-translational patterns and motifs
Physiochemical analysis, including molecular weight,
theoretical pI, amino acid composition, instability index,
aliphatic index and the grand average of hydropathicity (GRAVY) of
Per a 9 was performed using the ProtParam tool (http://web.expasy.org/protparam/), as previously
described (33). The Per a 9
characteristic pattern was examined for the original sequence and
further analysis was performed to highlight the presence of
functional motifs using the Prosite database (http://prosite.expasy.org/), as previously described
(34).
Secondary structure prediction
Per a 9 secondary structural elements recognition
was assessed by PSIPRED (bioinf.cs.ucl.ac.uk/psipred), which threads sequence
segments through Protein Data Bank (PDB) library (http://www.pdb.org/) to identify conserved
substructures (35). Furthermore,
the secondary structure elements were also identified and compared
with the results obtained with NetSurfP ver. 1.1 (www.cbs.dtu.dk) (36).
Homology modeling and validation
The Per a 9 protein sequence was searched for
homology in the PDB (http://www.rcsb.org/). In addition, the homologous
templates suitable for Per a 9 were selected using the PSI-BLAST
server (http://blast.ncbi.nlm.nih.gov/Blast.cgi) in the NCBI
and Swiss-model server (http://swissmodel.expasy.org/). The best templates
were retrieved from the results of PSI-BLAST and used for homology
modeling. The Der f 25 modeled protein structure was built through
Alignment Mode in SWISS-MODEL (http://swissmodel.expasy.org/) using the complete
amino acid sequence. An initial structural model was generated and
checked for recognition of errors in 3D structure by PROCHECK
(37), ERRAT (verification of
protein structures: patterns of nonbonded atomic interactions)
(33,38) and VERIFY_3D (a method to identify
protein sequences that fold into a known three-dimensional
structure. Assessment of protein models with three-dimensional
profiles) programs in Structural Analysis and Verification Server
(http://nihserver.mbi.ucla.edu/SAVES/)
(33,38).
In silico prediction of B cell
epitopes
Three immunoinformatics tools, including the DNASTAR
Protean system (39),
Bioinformatics Predicted Antigenic Peptides (BPAP) system
(http://imed.med.ucm.es/Tools/antigenic.pl) and the
BepiPred 1.0 server (http://www.cbs.dtu.dk/services/BepiPred/) were used to
predict the B cell epitopes of Per a 9, as previously described
(40). The ultimate consensus
epitope results were obtained by combining the results of the three
tools together with a previously published method (41). If the results of all 3 methods
were non-epitope, then the consensus result was 0% epitope.
Similarly, if the predicted results had only one or no non-epitope,
the consensus result was 67 or 100% epitope, respectively. Finally,
the regions whose consensus epitope result was 67 or 100% were
selected as the final potential epitope regions. In the DNAStar
Protean system, 4 properties (hydrophilicity, flexibility,
accessibility and antigenicity) of the amino acid sequence were
selected as parameters for epitope prediction. The peptide regions
with good hydrophilicity, high flexibility, surface accessibility
and high antigenic index were selected as candidate epitopes for
further investigation. The BPAP system and BepiPred 1.0 server only
need the amino acid sequence and provide more straightforward
results, which combined with the physicochemical properties of
amino acids such as hydrophilicity, flexibility, accessibility,
turns and exposed surface (42).
In silico prediction of T cell
epitopes
T cell epitopes are principally predicted indirectly
by identifying the binding of peptide fragments to the MHC
complexes. However, the binding grooves of MCH-II molecules are
open at both ends allowing various lengths of peptides to bind. On
the other hand, the same MHC molecule can accommodate a variety of
binding sequences. These two properties make the development of
accurate predictive algorithms for MHC-class II binding complex.
For HLA-DR-based T cell epitope prediction, the artificial neural
network-based alignment (NN-align) method NetMHCIIpan-3.0
(http://www.cbs.dtu.dk/services/NetMHCIIpan/) was
applied (43). For HLA-DQ
alleles, NetMHCII-2.2 (http://www.cbs.dtu.dk/services/NetMHCII/) was used
(44). Although HLA-DQ provides
limited binding-affinity data, it was recently reported to provide
the optimal performance in predicting this locus (33). The binding significance of each
peptide to the given MHC molecule is based on the estimated
strength of binding exhibited by a predicted nested core peptide at
a set threshold level. For HLA-DR-based T cell epitope prediction,
HLA-DR 101, HLA-DR 301, HLA-DR 401 and HLA-DR 501 were used. The
ultimate HLA-DR-based T cell epitope results were obtained by
combining those 4 results together and if 3 of these were shown to
be epitope, the consensus result was then considered epitope. This
method was also used in HLA-DQ-based T cell epitope prediction. For
HLA-DQ-based T cell epitope prediction, only HLA-DQA10501-DQB10201,
HLA-DQA10301-DQB10302, HLA-DQA10401-DQB10402 and
HLA-DQA10102-DQB10602 were used. As a result, the ultimate
consensus epitope results were obtained by combining the results of
the HLA-DR-based T cell epitope and HLA-DQ-based T cell epitope. B
cell and T cell epitopes identified by computational tools were
mapped onto linear sequence and on the 3 dimensional model of Per a
9 in order to determine their position and secondary structure
elements involved.
Statistical analysis
Data are expressed as the means ± SE for the
indicated number of independently performed duplicated experiments.
Statistical significance between means was analyzed by one-way
ANOVA or the Student's t-test utilizing the SPSS 13.0 version. A
value of P<0.05 was considered to indicate a statistically
significant difference.
Results
Cloning of cDNA encoding full length Per
a 9 sequence
cDNA encoding Per a 9 was amplified by PCR using
primers based on the no-coding sequence of Per a 9 gene. It is a
1,074 bp gene and encodes a 356 amino acid protein (Fig. 1). The sequence homology with the
published one (Accession no. AY563004) was 99% (353/356) at the
protein level.
Expression and purification of Per a 9 in
E. coli
The Per a 9 gene was subcloned into the pET15b
vector and transformed into the ArcticExpress™ (DE3) RP host
strain. Per a 9 was expressed at 15, 25 or 37°C following
induction. Since Per a 9 was expressed in a soluble form in the
supernatant at 15°C (Fig. 2A),
the condition of 1 mM IPTG and 15°C was selected as the final
condition throughout the study. The Per a 9 protein was purified by
Ni column. More than 8.69 mg recombinant Per a 9 was obtained from
1 liter of cell culture. The purity of the purified Per a 9 was
identified by SDS-PAGE. It showed a single band with an apparent
molecular weight of 40 kDa (Fig.
2B).
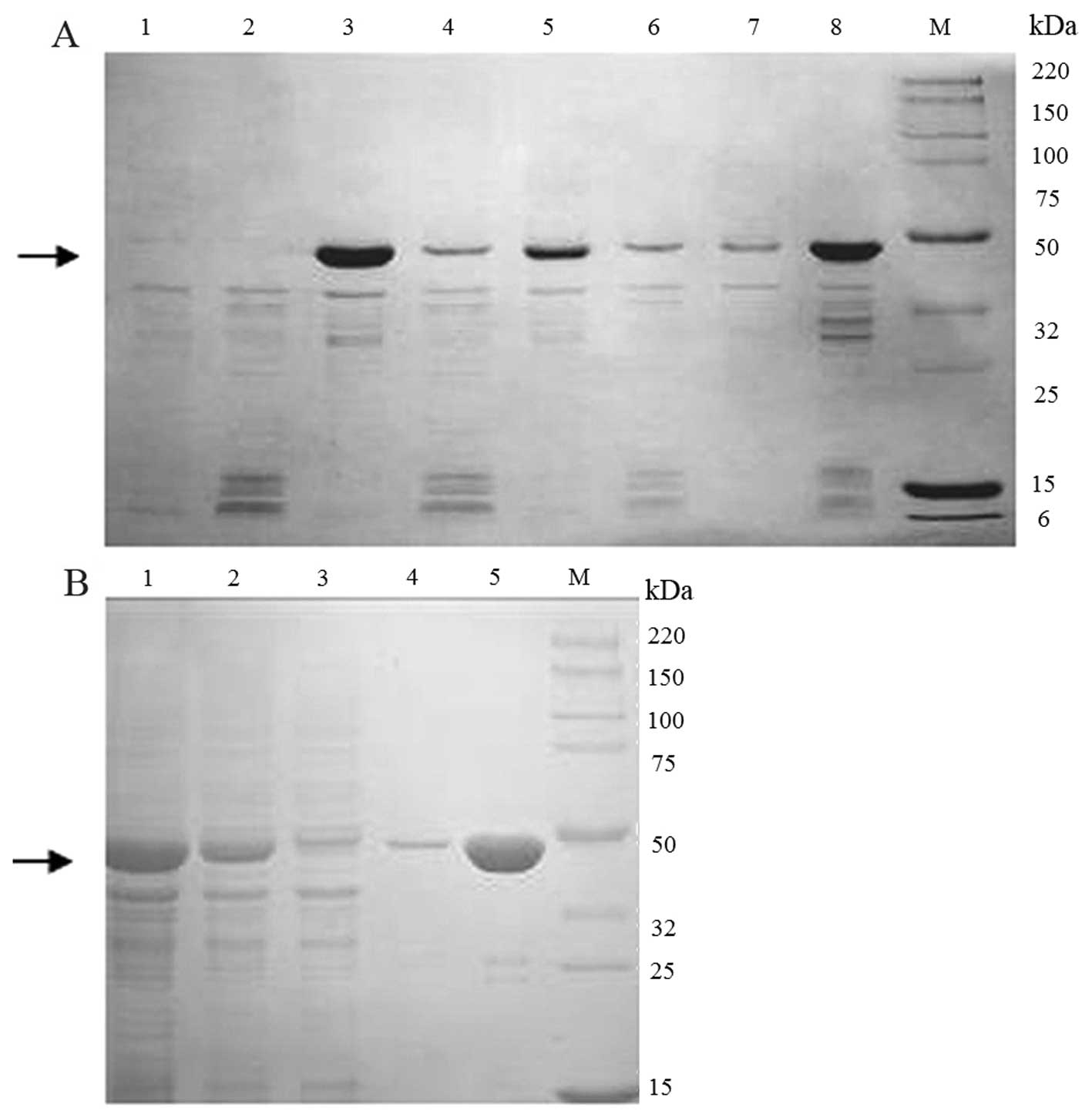 | Figure 2Expression and purification of Per a
9 in E. coli. (A) Per a 9 expressed at 15, 25 or 37°C was
analyzed by sodium dodecyl sulfate-polyacrylamide gel
electrophoresis (SDS-PAGE). Lane M, Smart Broad-Range protein
standard (Genscript, Nanjing, China); lane 1, the supernatant of
un-induced cells; lane 2, the precipitant of un-induced cells; lane
3, the supernatant of the cells induced at 15°C; lane 4, the
precipitant of the cells induced at 15°C; lane 5, the supernatant
of the cells induced at 25°C; lane 6, the precipitant of the cells
induced at 25°C; lane 7, the supernatant of the cells induced at
37°C; lane 8, the precipitant of the cells induced at 37°C. The
arrow represents Per a 9 protein. (B) SDS-PAGE analysis of purified
Per a 9 expressed in E. coli. Lane M, protein standard; lane
1, total protein after sonication; lane 2, the supernatant after
centrifugation; lane 3, flow through; lane 4, washing with 50 mM
imidazole; lane 5, washing with 250 mM imidazole. The arrow
represents Per a 9 protein. |
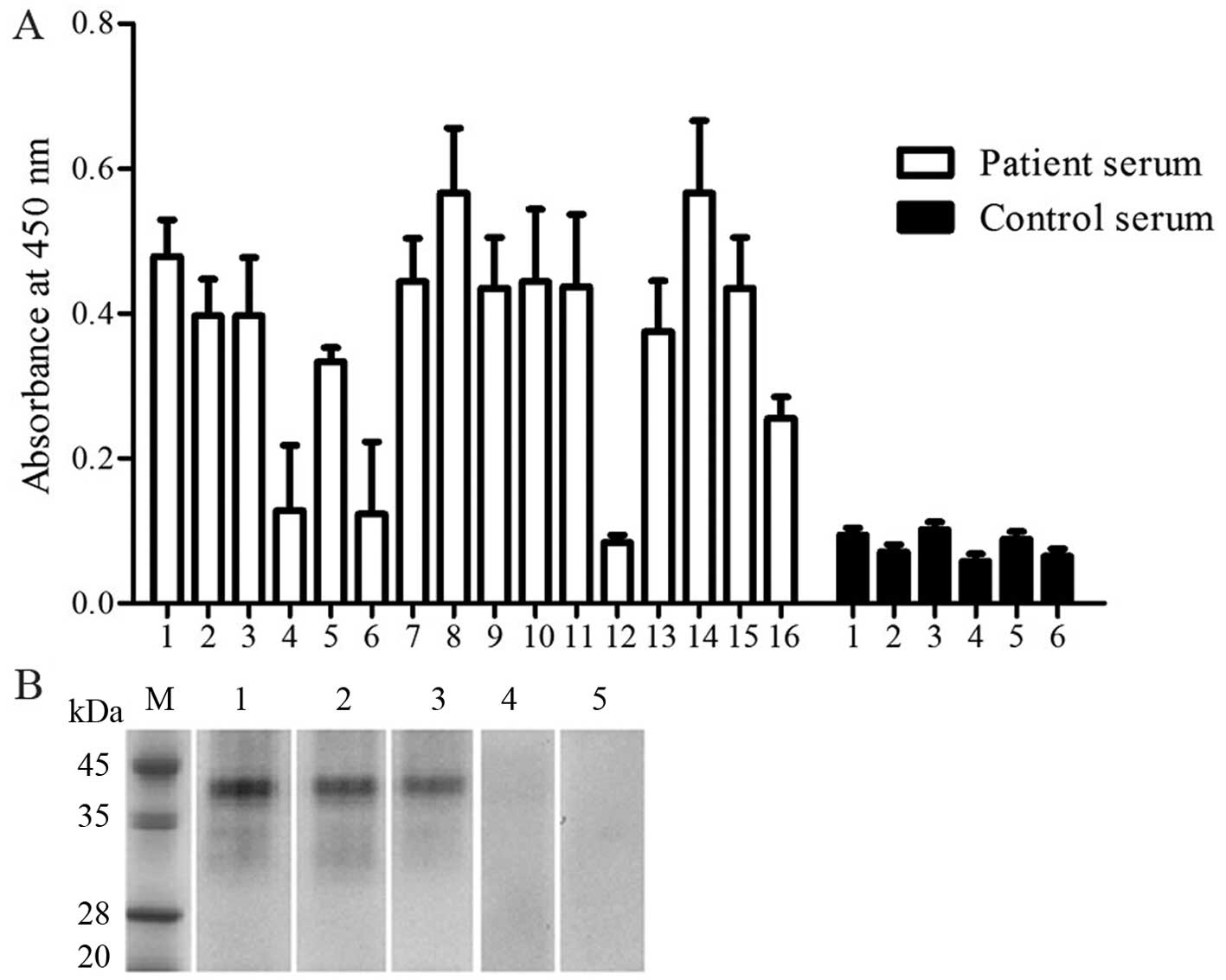
Immunoreactivity to IgE
In order to determine the allergenicity of Per a 9,
we examined the ability of Per a 9 to bind IgE in the sera of the
patients with American CR allergies using a direct ELISA technique.
The sera from all patients apart from patients 4, 6 and 12
exhibited a positive IgE reactivity to Per a 9. The results
revealed that 13/16 (81.3%) sera from these patients reacted to Per
a 9 (Fig. 3A). The IgE binding
activity of Per a 9 in a representative group of 3 patients and 2
healthy controls were assessed by western blot analysis and the
results are illustrated in Fig.
3B.
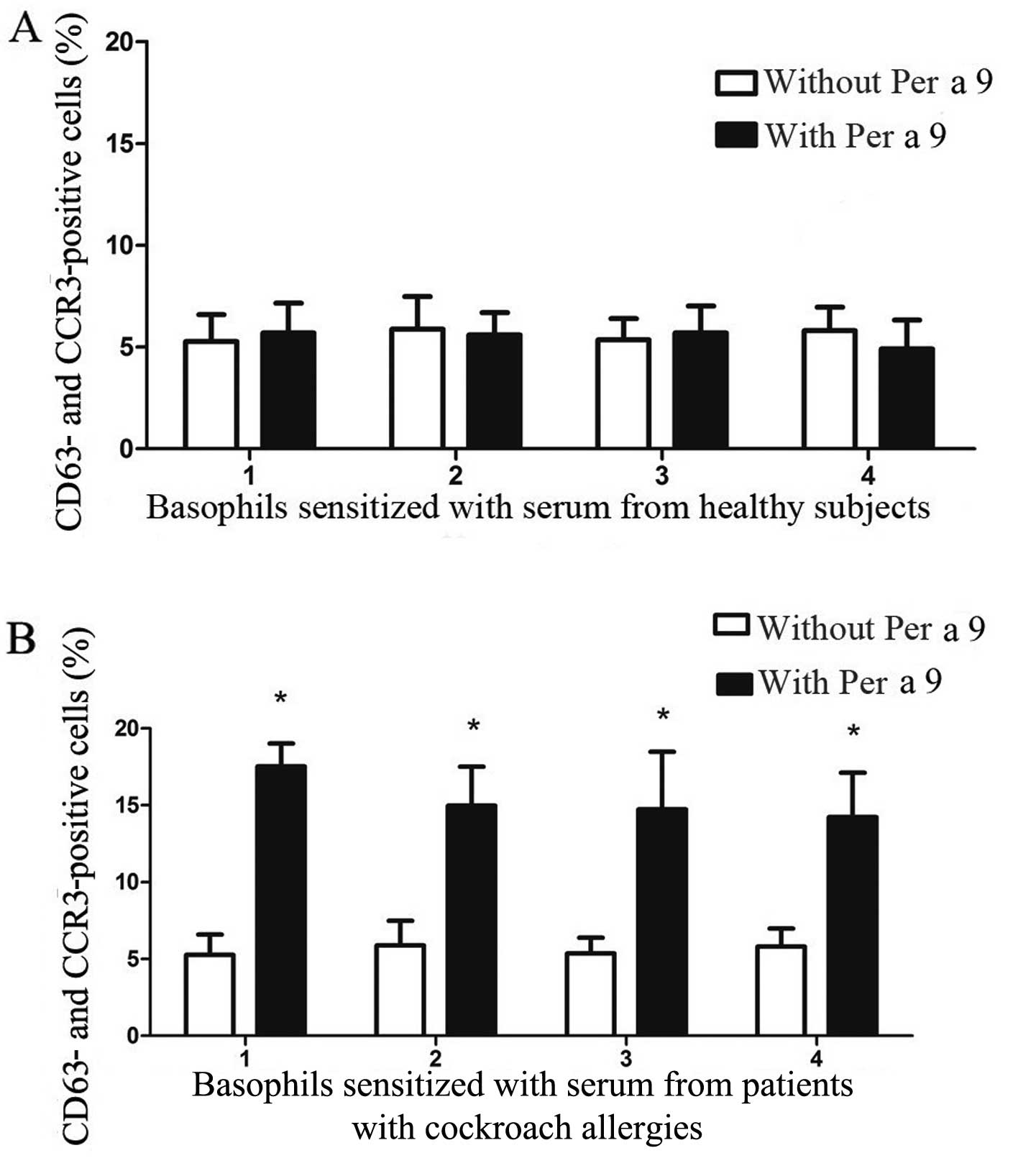
Per a 9 induces basophil activation
Per a 9 at 1.0 μg/ml induced approximately up
to a 4.2-fold increase in the number of CD63 and CCR3
double-positive cells when incubating with passively sensitized
basophils from the sera of patients with American CR allergies. Per
a 9 had no effect on the basophils sensitized by the sera from HC
(Fig. 4).
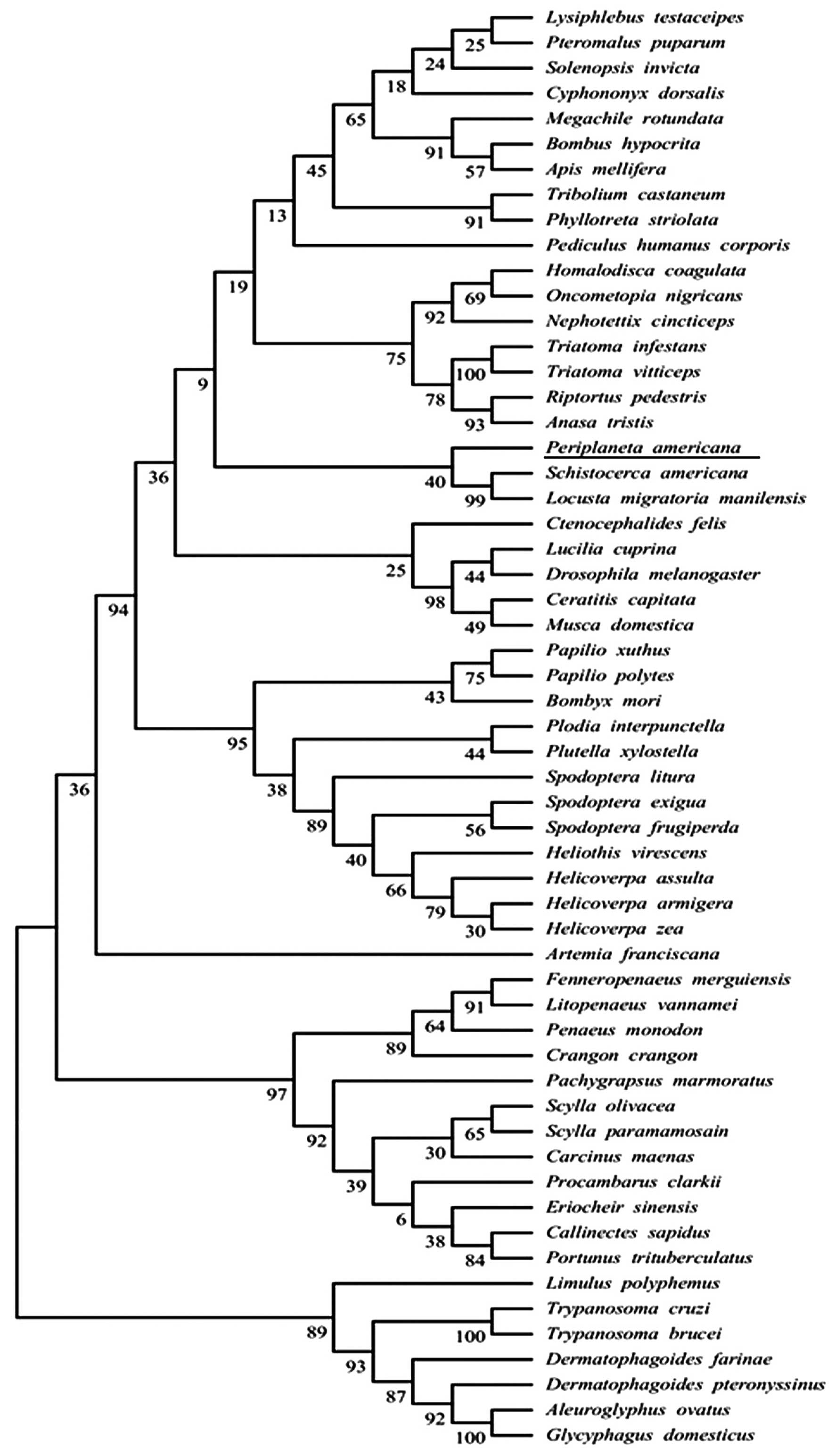
Sequence retrieval and phylogenetic
analysis
Uniprot and tBLASTn were used to search the
homologous sequences of Per a 9. As a result, 47 sequences were
obtained. In order to determine the relationships between Per a 9
and its homologous sequences, phylogenetic analysis was performed
and the evolutionary tree inferred by the ML method is presented in
Fig. 5.
Physiochemical analyses,
post-translational patterns and motifs
The primary structure of Per a 9 contained 356 amino
acids and the molecular weight was 39,735. The theoretical pI was
5.58 and the aliphatic index was 80.56. The GRAVY was -0.413, which
incidated that Per a 9 exhibited a hydrophilic character. The
instability index was 31.36 (<40), indicating that the Per a 9
protein was stable. Per a 9 is an arginine kinase and the results
from PROSITE showed that Per a 9 had two obvious characteristic
patterns of phosphagen kinase, including PS51509 (phosphagen kinase
N-terminal domain profile) and PS51510 (phosphagen kinase
C-terminal domain profile). Moreover, PS00112 was contained in
PS51510 and consisted of CPTNLGT, which was the active center of
phosphagen kinase. The ATP-binding sites were His (185) and Arg
(229).
Structural analysis of Per a 9
Secondary structure prediction with PSIPRED
identified 11 α-helices and 8 β-sheets in Per a 9. PredictProtein
predicted 10 α-helices and 9 β-sheets. Alternatively, NetSurfP v1.1
predicted 11 α-helices and 9 β-sheets. The predicated secondary
structure of Per a 9 is presented in Table I.
 | Table IThe predicated secondary structure of
Per a 9. |
Table I
The predicated secondary structure of
Per a 9.
| Secondary
structural prediction methods | α-helices | β-sheets |
|---|
| PSIPRED | 3–12, 25–18, 32–39,
50–56, 73–89, 142–156, 174–183, 193–197, 240–255, 294–303,
35–354 | 66–68, 210–213,
218–223, 229–234, 260–261, 266–268, 279–286, 322–324 |
| NetSurfP
ver1.1 | 2–12, 25–28, 32–40,
50–56, 74–89, 142–157, 175–183, 193–197, 239–256, 294–303,
333–354 | 65–69, 120–128,
209–213, 217–223, 227–233, 267–269, 279–286, 307–310, 322–326 |
| PredictProtein | 4–13, 25–28, 32–39,
50–53, 78–89, 142–157, 175–183, 239–256, 294–303, 335–355 | 65–69, 167–170,
208–213, 217–222, 232–234, 267–270, 279–287, 307–311, 322–326 |
| Overall
results | 3–12, 25–28, 32–39,
50–56, 74–89, 142–157, 175–183, 193–197, 239–256, 294–303,
335–354 | 65–69, 120–123,
210–213, 218–223, 228–234, 260–261, 280–286, 307–310, 322–326 |
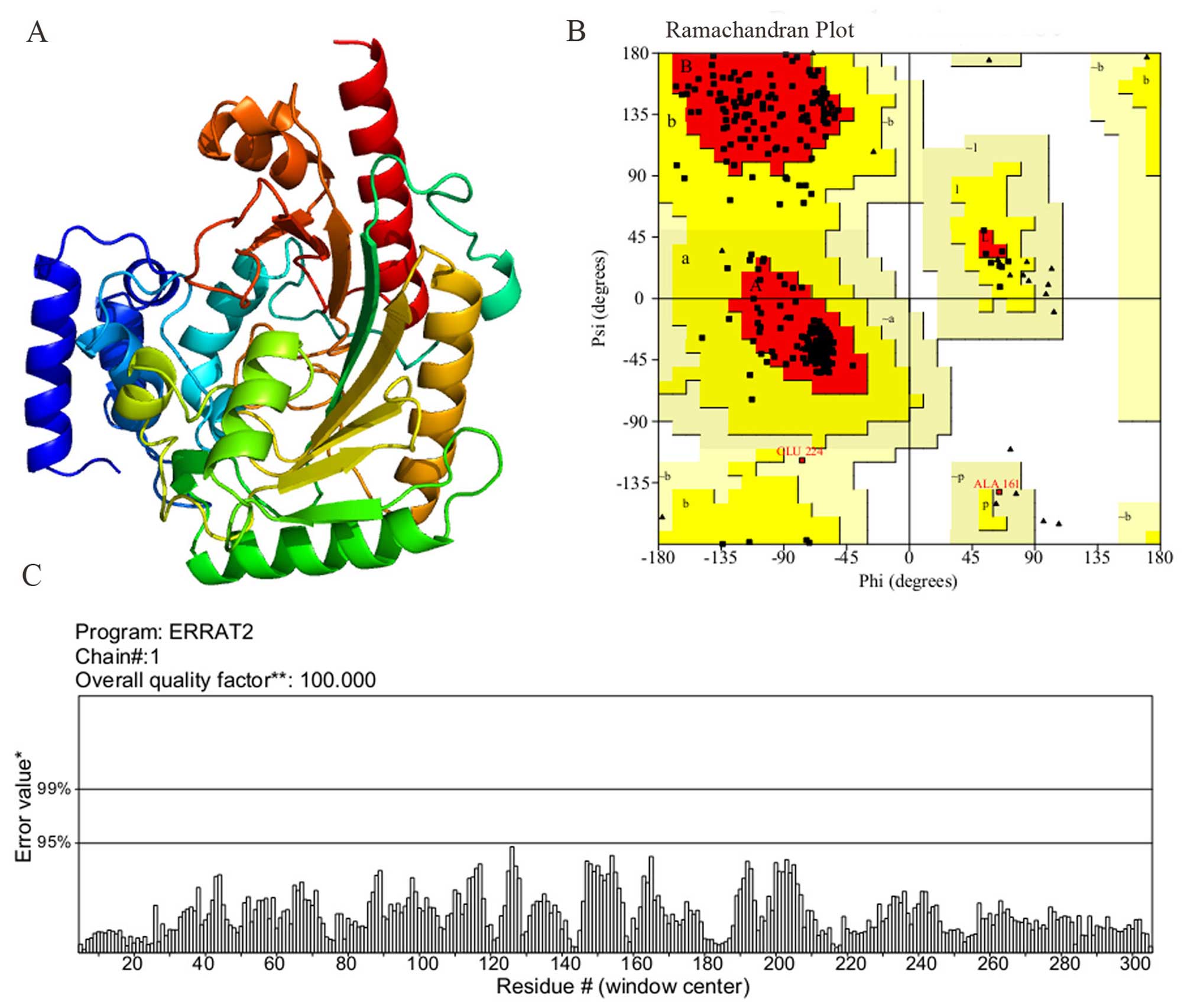
Homology modeling and validation
The search for the proteins of Per a 9 with known
tertiary structure in the PDB yielded Litopenaeus vannamei
arginine kinase (PDB Accession no. 4BG4) showing the highest
sequence identity (83% with Per a 9). As a result, the 4BG4
template was used for homology modeling. The homology model that
matched the aforementioned structures is shown in Fig. 6A. As indicated by the Ramachandran
plot (Fig. 6B), 89.4% of the
residues in the model structure were within the most favored
regions, 10% of the residues were in the additional allowed region,
0.6% of the residues were in the generously allowed regions and 0%
of the residues were in the disallowed region. As indicated by the
ERRAT program, the results (Fig.
6C) revealed that the overall quality factor was 100, which
indicated that the structure had a high resolution. As indicated by
the VERIFY_3D program, the results revealed that 99.72% of the
residues had an average 3D (atomic model)-1D (amino acid sequence)
score of >0.2, which also indicated that the structure was good.
Based on these validations, it is shown that the homology model was
adopted for this study.
B cell epitope prediction
Surface accessibility and fragment flexibility are
important features for predicting antigenic epitopes. In addition,
the existence of regions with high hydrophobicity also provides
strong evidence of epitope identification. The antigenic index
directly revealed the epitope forming capacity of the Per a 9
sequence. Based on these sequence properties, the final predicting
regions of Per a 9 by DNASTAR were obtained as: 23–31, 38–46,
57–64, 70–72, 91–117, 143–154, 159–165, 174–183, 189–19, 222–227,
292–302, 309–32 and 337–345. The predicted results of the BPAP
system were 19–20, 39–46, 58–74, 90–118, 131–136, 145–154, 157–165,
175–176, 275–278, 290–292, 295–299, 309–325 and 338–344. The
predicted results of the BepiPred 1.0 server were 11–19, 21–28,
46–55, 115–127, 134–142, 152–158, 176–187, 193–203, 216–222,
238–251, 264–273, 277–293 and 296–308. Furthermore, the final
potential B cell epitopes of Per a 9 were selected on the basis of
the results of these 3 tools. The ultimate results of the 3
immunoinformatics tools finally predicted 11 peptides (23–28,
39–46, 58–64, 91–118, 131–136, 145–154, 159–165, 176–183, 290–299,
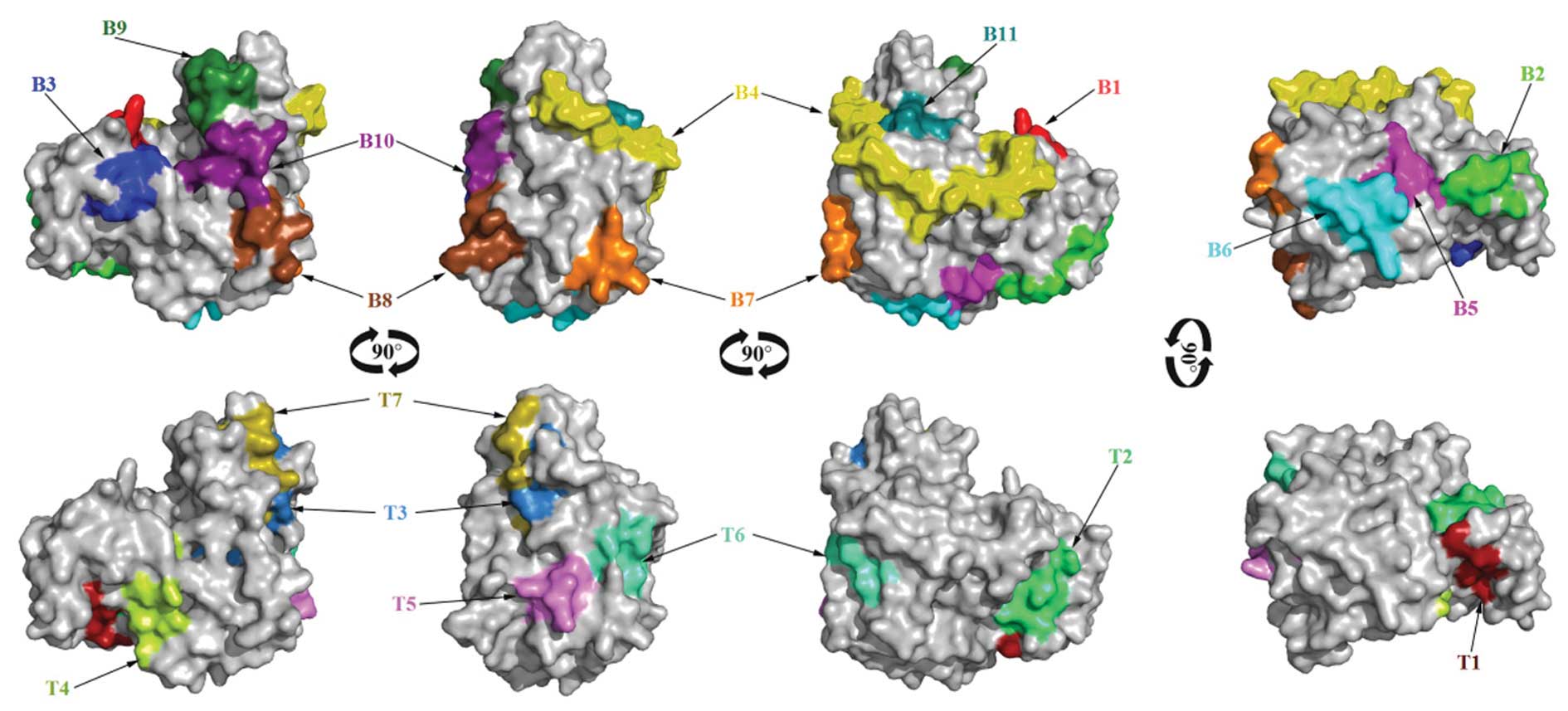
309–320 and 338–344) and these peptides are shown in Fig. 7.
T cell epitope prediction
For the HLA-DR-based T cell epitope prediction of
Per a 9, the final predicting regions of HLA-DR 101, HLA-DR 301,
HLA-DR 401 and HLA-DR 501 are shown in Table II and the ultimate results of
HLA-DR-based T cell epitope prediction finally predicted 5 peptides
(119–127, 194–202, 210–218, 239–250 and 279–290). For HLA-DQ
alleles, the final results of HLA-DQA10101-DQB10501,
HLA-DQA10301-DQB10302, HLA-DQA10401-DQB10402, and
HLA-DQA10102-DQB10602 are also shown in Table II and the ultimate results of
these 4 methods finally predicted 2 peptides, 46–54 and 65–80. As a
result, Per a 9 was predicted to have 7 T cell epitope sequences,
46–54, 65–80, 119–127, 194–202, 210–218, 239–250 and 279–290 as
shown in Fig. 7.
| Table IIThe T cell epitope prediction of Per
a 9. |
Table II
The T cell epitope prediction of Per
a 9.
| HLA types | Location of the
prediction results |
|---|
| HLA-DR 101 | 7–15, 14–22, 17–25,
23–31, 26–34, 29–37, 35–43, 40–48, 45–53, 46–54, 48–56, 50–58,
67–75, 78–86, 100–108, 117–125, 119–127, 123–131, 128–136, 136–144,
153–161, 156–164, 166–174, 167–175, 168–176, 186–194, 192–200,
194–202, 195–203, 201–209, 210–218, 227–235, 231–239, 238–246,
242–250, 267–275, 268–276, 273–281, 275–283, 277–285, 278–286,
279–287, 282–290, 287–295, 289–297, 290–298, 303–311, 304–312,
305–313, 308–316, 342–350, 348–356, |
| HLA-DR 301 | 68–76, 77–85,
180–188, 211–219, 210–218, 259–267 |
| HLA-DR401 | 26–34, 29–37,
48–56, 49–57, 119–127, 120–128, 170–178, 194–202, 227–235, 228–236,
231–239, 239–247, 242–250, 245–253, 279–287, 282–290, 283–291,
346–354 |
| HLA-DR501 | 8–16, 14–22, 19–27,
22–30, 24–32, 35–43, 118–126, 119–127, 167–175, 185–193, 186–194,
194–202, 195–203, 200–208, 210–218, 239–247, 243–251, 267–275,
278–286, 282–290, 283–291, 284–292, 286–294, 288–296, 289–297,
304–312, 322–330, |
|
HLA-DQA10501-DQB10201 | 46–54, 67–75,
65–73, 74–82, 77–85, 186–194, 218–226, 220–228 |
|
HLA-DQA10301-DQB10302 | 65–73, 71–79,
72–80, 73–81, 79–87, 154–162, 214–222 |
|
HLA-DQA10501-DQB10301 | 2–10, 7–15, 10–18,
12–20, 13–21, 16–24, 44–52, 46–54, 61–69, 66–74, 71–79, 72–80,
89–97, 115–123, 125–133, 169–177, 194–202, 195–203, 212–220,
234–242, 237–245, 243–251, 274–282, 279–287, 283–291, 292–300,
308–316, 218–226, 242–250 |
|
HLA-DQA10102-DQB10602 | 12–20, 45–53,
48–56, 62–70, 72–80, 120–128, 154–162, 189–197, 192–200, 195–203,
214–222, 225–233, 228–236, 274–282, 347–355 |
| The final predicted
T cell epitopes | 46–54, 65–80,
119–127, 194–202, 210–218, 239–250, 279–290 |
Discussion
To better understand the Per a 9-mediated CR
allergies and with an aim to improve the diagnosis and treatment of
CR allergies, we prepared biologically active and highly pure
American CR allergen Per a 9 in relatively large amount in the
present study. Per a 9, an arginine kinase, has been reported to be
purified from American CR extract by monoclonal antibody
based-affinity chromatography (12), but the quantity obtained was
limited. Since monoclonal antibody based-affinity chromatography is
very costly and tedious, it is not suitable for the production of
large amounts of target protein. We therefore prepared recombinant
Per a 9 using E. coli expression systems in the present
study. We found that as little as 1 liter of E. coli was
able to produce 8.69 mg of highly pure recombinant Per a 9, which
is sufficient for the functional analysis of Per a 9.
It is well known that the advantages of the
prokaryotic (E. coli) system are easy handling and the
expression of high-quantity of target proteins (45); however, one of the disadvantages
is that insoluble, inactive inclusion bodies are frequently formed,
which means that protein needs to be reconstituted in vitro
following solubilization under denaturing conditions to achieve
biological activity. Moreover, the application of non-glycosylated
recombinant allergens in allergy diagnosis frequently yields false
results, as the recombinant allergens lack glycan structures of
their natural counterparts, which IgE supposedly react with
(46). It has been discovered
that Per a 9 contains 356 amino acids with a calculated molecular
weight of 39.74 kDa, and Per a 9 purified from American CR extract
by monoclonal antibody based-affinity chromatography exhibits a
molecular weight of 40.57 kDa (12), indicating that few glycan
structures exist in Per a 9 protein. In the present study, Per a 9
expressed in the ArcticExpress™ (DE3) RP host strain was
soluble with a molecular weight of 40 kDa, without any
reconstitution process, indicating that Per a 9 obtained herein
should have its immunological and biological functions.
Our results showed that 81.3% of the sera from
patients with CR allergies reacted to Per a 9, proving that Per a 9
is a major allergen of the American CR. A similar finding has been
previously reported in the Thai population (12). The basophil activation test we
employed herein is a more advanced technique for the determination
of the allerginicity of a given compound. We confirmed that Per a 9
is an active allergen of CR as it was able to activate basophils
which were sensitized by CR allergy sera. The availability of
recombinant allergens has increased our understanding of
IgE-mediated allergies and may improve the diagnosis and treatment
of these diseases (47). In our
case, recombinant Per a 9 should be a useful tool for the
functional and clinical analysis of this allergen.
Allergen-specific IgE is the key molecule for the
development of allergic symptoms. The synthesis of IgE requires a B
cell to undergo class switch recombination in close contact with
allergen-specific T helper 2 cells (Th2) (48). In a previous study, overlapping
synthetic peptides were frequently used to validate the IgE-binding
capacity. Although this method decreases the possibility of missed
epitopes, it needs to synthesize lots of peptides and is very
costly and time-consuming (49).
In silico prediction has already become a familiar and
useful tool for selecting epitopes from immunologically relevant
proteins, which can save the expense of synthetic peptides and the
working time (50). A previous
study demonstrated that the use of the bioinformatics approach to
predict B cell epitopes correlated well with the experimental
approach (51). Many algorithms
have been developed to predict B cell epitopes on a protein
sequence based on the propensity values of amino acid properties of
hydrophilicity, antigenicity, segmental mobility, flexibility and
accessibility (48). In the
present study, we predicted the B cell linear epitopes of Per a 9
allergens by 3 sequence based tools (the DNASTAR protean system,
BPAP and the BepiPred 1.0 server) and predicted 11 peptides (23–28,
39–46, 58–64, 91–118, 131–136, 145–154, 159–165, 176–183, 290–299,
309–320 and 338–344) as potential B cell linear epitopes. Over the
past several years, some algorithms have substantially improved
their accuracy to predict T cell epitopes. However, most algorithms
have targeted HLA-DR molecules, but not HLA-DP and HLA-DQ
molecules, even though they are important for antigen presentation.
NetMHCpan-2.0 has recently been evaluated to have a per-allele mean
accuracy of 0.854 (1.0 being 100% accurate, and 0.5 of no
significance) (52). In another
study, the per-allele mean accuracy of NN-align was 0.882 (53). In this study, Net-MHCIIpan-2.0 and
NetMHCII-2.2 were used to predict the core 9-mer T cell epitopes in
the Per a 9 allergens and predicted 5 potential T cell epitope
sequences, 119–127, 194–202, 210–218, 239–250 and 279–290.
Allergen-specific immunotherapy (SIT) is the only
treatment able to cure allergic diseases. Numerous studies have
shown that crude allergen extracts currently used in SIT are
clinically effective (54–56);
a high allergen dose is more effective, although the potential risk
of severe acute side-effects is a limiting factor. Attenuated
allergenic molecules, i.e., hypoallergens or synthetic peptide
fragments have been used as high-dose and safer alternatives to
conventional extract-based SIT (57). Vaccination with a combination of
small peptides that together extend across the entire native
allergenic protein theoretically could preserve T cell activation,
while avoiding IgE-based immune responses. IgE recognizes
conformational epitopes of larger peptides (B cell epitopes) and
proteins, while T cell receptors recognize small linear peptides of
8 to 10 amino acids (T cell epitope). By immunizing with small
peptides, T cell activation could occur, while IgE binding would be
lost (58–60).
In conclusion, in the present study, we prepared
recombinant Per a 9 allergens using a prokaryotic expression
system. We confirm that Per a 9 is a major allergen of the American
CR, which can activate basophils in vitro. Recombinant Per a
9 may prove to be a useful tool for studying and understanding the
role of Per a 9 in CR allergies. We also predicted B and T cell
epitopes of the Per a 9 allergen, the major allergen in the
American CR, using the in silico method, which can be used
to benefit allergen immunotherapies and reduce the frequency of
allergic reactions. However, their accuracies need to be confirmed
in the further experiments.
Acknowledgments
This study was sponsored by grants from the Special
Fund for Forestry-scientific Research in the Public Interest (no.
201304103); the National Natural Science Foundation of China (nos.
81571568, 31340073 and 81273274); Jiangsu Province's Key Provincial
Talents Program (no. RC201170); the Priority Academic Program
Development of Jiangsu Higher Education Institutions (PAPD);
National 'Twelfth Five-Year' Plan for Science and Technology
Support Project (no. 2014BAI07B02); the Innovation team project of
Education Department of Liaoning Province (no. LT2013017); the
higher Education Climb scholars Program of Liaoning Province, China
(no. LJ2013222); and the Liaoning Province Translational Medicine
Research Center for Allergy (no. LK2013041).
References
|
1
|
Bernton HS and Brown H: Insect allergy
preliminary studies of the cockroach. J Allergy. 35:506–513. 1964.
View Article : Google Scholar : PubMed/NCBI
|
|
2
|
Arruda LK, Vailes LD, Ferriani VPL, Santos
AB, Pomés A and Chapman MD: Cockroach allergens and asthma. J
Allergy Clin Immunol. 107:419–428. 2001. View Article : Google Scholar : PubMed/NCBI
|
|
3
|
Sun BQ, Lai XX, Gjesing B, Spangfort MD
and Zhong NS: Prevalence of sensitivity to cockroach allergens and
IgE cross-reactivity between cockroach and house dust mite
allergens in Chinese patients with allergic rhinitis and asthma.
Chin Med J (Engl). 123:3540–3544. 2010.
|
|
4
|
Thangam Sudha V, Arora N, Sridhara S, Gaur
SN and Singh BP: Biopotency and identification of allergenic
proteins in Periplaneta americana extract for clinical
applications. Biologicals. 35:131–137. 2007. View Article : Google Scholar
|
|
5
|
He S, Zhang Z, Zhang H, Wei J, Yang L,
Yang H, Sun W, Zeng X and Yang P: Analysis of properties and
proinflammatory functions of cockroach allergens Per a 1.01s. Scand
J Immunol. 74:288–295. 2011. View Article : Google Scholar : PubMed/NCBI
|
|
6
|
Wu HQ, Liu ZG, Ran PX, Zhou ZW and Gao B:
Expression, purification, and immunological characterization of Cr
PI. Protein Pept Lett. 14:881–885. 2007. View Article : Google Scholar : PubMed/NCBI
|
|
7
|
Mindykowski B, Jaenicke E, Tenzer S, Cirak
S, Schweikardt T, Schild H and Decker H: Cockroach allergens Per a
3 are oligomers. Dev Comp Immunol. 34:722–733. 2010. View Article : Google Scholar : PubMed/NCBI
|
|
8
|
Tan YW, Chan SL, Ong TC, Yit Y, Tiong YS,
Chew FT, Sivaraman J and Mok YK: Structures of two major allergens,
Bla g 4 and Per a 4, from cockroaches and their IgE binding
epitopes. J Biol Chem. 284:3148–3157. 2009. View Article : Google Scholar
|
|
9
|
Wei JF, Yang H, Li D, Gao P and He S:
Preparation and identification of Per a 5 as a novel American
cockroach allergen. Mediators Inflamm. 591468:20142014.
|
|
10
|
Chen H, Yang HW, Wei JF and Tao AL: In
silico prediction of the T-cell and IgE-binding epitopes of Per a 6
and Bla g 6 allergens in cockroaches. Mol Med Rep. 10:2130–2136.
2014.PubMed/NCBI
|
|
11
|
Yang H, Kong X, Wei J, Liu C, Song W,
Zhang W, Wei W and He S: Cockroach allergen Per a 7 down-regulates
expression of Toll-like receptor 9 and IL-12 release from P815
cells through PI3K and MAPK signaling pathways. Cell Physiol
Biochem. 29:561–570. 2012. View Article : Google Scholar : PubMed/NCBI
|
|
12
|
Sookrung N, Chaicumpa W, Tungtrongchitr A,
Vichyanond P, Bunnag C, Ramasoota P, Tongtawe P, Sakolvaree Y and
Tapchaisri P: Periplaneta americana arginine kinase as a major
cockroach allergen among Thai patients with major cockroach
allergies. Environ Health Perspect. 114:875–880. 2006. View Article : Google Scholar : PubMed/NCBI
|
|
13
|
Sudha VT, Arora N, Gaur SN, Pasha S and
Singh BP: Identification of a serine protease as a major allergen
(Per a 10) of Periplaneta americana. Allergy. 63:768–776. 2008.
View Article : Google Scholar : PubMed/NCBI
|
|
14
|
Kang BC, Johnson J, Morgan C and Chang JL:
The role of immunotherapy in cockroach asthma. J Asthma.
25:205–218. 1988. View Article : Google Scholar : PubMed/NCBI
|
|
15
|
Srivastava D, Gaur SN, Arora N and Singh
BP: Clinicoimmunological changes post-immunotherapy with
Periplaneta americana. Eur J Clin Invest. 41:879–888. 2011.
View Article : Google Scholar : PubMed/NCBI
|
|
16
|
Sharma V, Singh BP, Gaur SN, Pasha S and
Arora N: Bioinformatics and immunologic investigation on B and T
cell epitopes of Cur l 3, a major allergen of Curvularia lunata. J
Proteome Res. 8:2650–2655. 2009. View Article : Google Scholar : PubMed/NCBI
|
|
17
|
Wang HW, Lin YC, Pai TW and Chang HT:
Prediction of B-cell linear epitopes with a combination of support
vector machine classification and amino acid propensity
identification. J Biomed Biotechnol. 2011:4328302011. View Article : Google Scholar : PubMed/NCBI
|
|
18
|
Nielsen M, Lund O, Buus S and Lundegaard
C: MHC class II epitope predictive algorithms. Immunology.
130:319–328. 2010. View Article : Google Scholar : PubMed/NCBI
|
|
19
|
An S, Chen L, Wei JF, Yang X, Ma D, Xu X,
Xu X, He S, Lu J and Lai R: Purification and characterization of
two new allergens from the venom of Vespa magnifica. PLoS One.
7:e319202012. View Article : Google Scholar : PubMed/NCBI
|
|
20
|
An S, Ma D, Wei JF, Yang X, Yang HW, Yang
H, Xu X, He S and Lai R: A novel allergen Tab y 1 with inhibitory
activity of platelet aggregation from salivary glands of
horseflies. Allergy. 66:1420–1427. 2011. View Article : Google Scholar : PubMed/NCBI
|
|
21
|
Sanz ML, Gamboa PM, Antépara I, Uasuf C,
Vila L, Garcia-Avilés C, Chazot M and De Weck AL: Flow cytometric
basophil activation test by detection of CD63 expression in
patients with immediate-type reactions to betalactam antibiotics.
Clin Exp Allergy. 32:277–286. 2002. View Article : Google Scholar : PubMed/NCBI
|
|
22
|
Sainte-Laudy J, Vallon C and Guérin JC:
Analysis of membrane expression of the CD63 human basophil
activation marker. Applications to allergologic diagnosis. Allerg
Immunol (Paris). 26:211–214. 1994.In French.
|
|
23
|
Liu F, Wei XL, Li H, Wei JF, Wang YQ and
Gong XJ: Molecular evolution of the vertebrate FK506 binding
protein 25. Int J Genomics. 2014:4026032014. View Article : Google Scholar : PubMed/NCBI
|
|
24
|
Yang L, Luo Y and Wei J: Integrative
genomic analyses on Ikaros and its expression related to solid
cancer prognosis. Oncol Rep. 24:571–577. 2010. View Article : Google Scholar : PubMed/NCBI
|
|
25
|
Yang L, Luo Y, Wei J and He S: Integrative
genomic analyses on IL28RA, the common receptor of interferon-λ1,
-λ2 and -λ3. Int J Mol Med. 25:807–812. 2010.PubMed/NCBI
|
|
26
|
Yang L, Wei J and He S: Integrative
genomic analyses on interferon-λs and their roles in cancer
prediction. Int J Mol Med. 25:299–304. 2010.PubMed/NCBI
|
|
27
|
Yu H, Yuan J, Xiao C and Qin Y:
Integrative genomic analyses of recepteur d'origine nantais and its
prognostic value in cancer. Int J Mol Med. 31:1248–1254.
2013.PubMed/NCBI
|
|
28
|
Wang M, Wei X, Shi L, Chen B, Zhao G and
Yang H: Integrative genomic analyses of the histamine H1 receptor
and its role in cancer prediction. Int J Mol Med. 33:1019–1026.
2014.PubMed/NCBI
|
|
29
|
Wang B, Chen K, Xu W, Chen D, Tang W and
Xia TS: Integrative genomic analyses of secreted protein acidic and
rich in cysteine and its role in cancer prediction. Mol Med Rep.
10:1461–1468. 2014.PubMed/NCBI
|
|
30
|
Wang B, Xu W, Tan M, Xiao Y, Yang H and
Xia TS: Integrative genomic analyses of a novel cytokine,
interleukin-34 and its potential role in cancer prediction. Int J
Mol Med. 35:92–102. 2015.
|
|
31
|
Jin M, Yang HW, Tao AL and Wei JF:
Evolution of the protease-activated receptor family in vertebrates.
Int J Mol Med. 37:593–602. 2016.PubMed/NCBI
|
|
32
|
Ding Z, Yang HW, Xia TS, Wang B and Ding
Q: Integrative genomic analyses of the RNA-binding protein, RNPC1,
and its potential role in cancer prediction. Int J Mol Med.
36:473–484. 2015.PubMed/NCBI
|
|
33
|
Li X, Yang HW, Chen H, Wu J, Liu Y and Wei
JF: In silico prediction of T and B cell epitopes of Der f 25 in
dermatophagoides farinae. Int J Genomics. 2014:4839052014.
View Article : Google Scholar : PubMed/NCBI
|
|
34
|
Sigrist CJE, de Castro L, Cerutti BA,
Cuche N, Hulo A, Bridge L, Bougueleret L and Xenarios I: New and
continuing developments at PROSITE. Nucleic Acids Res. 41(Database
issue): D344–D347. 2013. View Article : Google Scholar :
|
|
35
|
McGuffin LJ, Bryson K and Jones DT: The
PSIPRED protein structure prediction server. Bioinformatics.
16:404–405. 2000. View Article : Google Scholar : PubMed/NCBI
|
|
36
|
Petersen B, Petersen TN, Andersen P,
Nielsen M and Lundegaard C: A generic method for assignment of
reliability scores applied to solvent accessibility predictions.
BMC Struct Biol. 9:512009. View Article : Google Scholar : PubMed/NCBI
|
|
37
|
Laskowski RA, MacArthur MW and Thornton
JM: Validation of protein models derived from experiment. Curr Opin
Struct Biol. 8:631–639. 1998. View Article : Google Scholar : PubMed/NCBI
|
|
38
|
Maganti L, Manoharan P and Ghoshal N:
Probing the structure of Leishmania donovani chagasi DHFR-TS:
comparative protein modeling and protein-ligand interaction
studies. J Mol Model. 16:1539–1547. 2010. View Article : Google Scholar : PubMed/NCBI
|
|
39
|
Burland TG: DNASTAR's Lasergene sequence
analysis software. Methods Mol Biol. 132:71–91. 2000.
|
|
40
|
Larsen JE, Lund O and Nielsen M: Improved
method for predicting linear B-cell epitopes. Immunome Res.
2:22006. View Article : Google Scholar : PubMed/NCBI
|
|
41
|
Yang X and Yu X: An introduction to
epitope prediction methods and software. Rev Med Virol. 19:77–96.
2009. View Article : Google Scholar
|
|
42
|
Zheng LN, Lin H, Pawar R, Li ZX and Li MH:
Mapping IgE binding epitopes of major shrimp (Penaeus monodon)
allergen with immunoinformatics tools. Food Chem Toxicol.
49:2954–2960. 2011. View Article : Google Scholar : PubMed/NCBI
|
|
43
|
Karosiene E, Rasmussen M, Blicher T, Lund
O, Buus S and Nielsen M: NetMHCIIpan-3.0, a common pan-specific MHC
class II prediction method including all three human MHC class II
isotypes, HLA-DR, HLA-DP and HLA-DQ. Immunogenetics. 65:711–724.
2013. View Article : Google Scholar : PubMed/NCBI
|
|
44
|
Nielsen M and Lund O: NN-align. An
artificial neural network-based alignment algorithm for MHC class
II peptide binding prediction. BMC Bioinformatics. 10:2962009.
View Article : Google Scholar : PubMed/NCBI
|
|
45
|
Wallner M, Gruber P, Radauer C, Maderegger
B, Susani M, Hoffmann-Sommergruber K and Ferreira F: Lab scale and
medium scale production of recombinant allergens in Escherichia
coli. Methods. 32:219–226. 2004. View Article : Google Scholar : PubMed/NCBI
|
|
46
|
Malandain H: IgE-reactive carbohydrate
epitopes - classification, cross-reactivity, and clinical impact.
Eur Ann Allergy Clin Immunol. 37:122–128. 2005.PubMed/NCBI
|
|
47
|
Schmidt M and Hoffman DR: Expression
systems for production of recombinant allergens. Int Arch Allergy
Immunol. 128:264–270. 2002. View Article : Google Scholar : PubMed/NCBI
|
|
48
|
Pomés A: Relevant B cell epitopes in
allergic disease. Int Arch Allergy Immunol. 152:1–11. 2010.
View Article : Google Scholar :
|
|
49
|
Lin J, Bardina L, Shreffler WG, Andreae
DA, Ge Y, Wang J, Bruni FM, Fu Z, Han Y and Sampson HA: Development
of a novel peptide microarray for large-scale epitope mapping of
food allergens. J Allergy Clin Immunol. 124:315–322. e3132009.
View Article : Google Scholar : PubMed/NCBI
|
|
50
|
Li GF, Wang Y, Zhang ZS, Wang XJ, Ji MJ,
Zhu X, Liu F, Cai XP, Wu HW and Wu GL: Identification of
immunodominant Th1-type T cell epitopes from Schistosoma japonicum
28 kDa glutathione-S-transferase, a vaccine candidate. Acta Biochim
Biophys Sin (Shanghai). 37:751–758. 2005. View Article : Google Scholar
|
|
51
|
Nair S, Kukreja N, Singh BP and Arora N:
Identification of B cell epitopes of alcohol dehydrogenase allergen
of Curvularia lunata. PLoS One. 6:e200202011. View Article : Google Scholar : PubMed/NCBI
|
|
52
|
Nielsen M, Justesen S, Lund O, Lundegaard
C and Buus S: NetMHCIIpan-2.0 - Improved pan-specific HLA-DR
predictions using a novel concurrent alignment and weight
optimization training procedure. Immunome Res. 6:92010. View Article : Google Scholar : PubMed/NCBI
|
|
53
|
Wang P, Sidney J, Kim Y, Sette A, Lund O,
Nielsen M and Peters B: Peptide binding predictions for HLA DR, DP
and DQ molecules. BMC Bioinformatics. 11:5682010. View Article : Google Scholar : PubMed/NCBI
|
|
54
|
Akdis CA and Akdis M: Advances in allergen
immunotherapy: aiming for complete tolerance to allergens. Sci
Transl Med. 7:280ps62015. View Article : Google Scholar : PubMed/NCBI
|
|
55
|
Soyka MB, van de Veen W, Holzmann D, Akdis
M and Akdis CA: Scientific foundations of allergen-specific
immunotherapy for allergic disease. Chest. 146:1347–1357. 2014.
View Article : Google Scholar : PubMed/NCBI
|
|
56
|
Jutel M and Akdis CA: Novel immunotherapy
vaccine development. Curr Opin Allergy Clin Immunol. 14:557–563.
2014. View Article : Google Scholar : PubMed/NCBI
|
|
57
|
Passalacqua G and Canonica GW: Specific
immunotherapy in asthma: Efficacy and safety. Clin Exp Allergy.
41:1247–1255. 2011. View Article : Google Scholar : PubMed/NCBI
|
|
58
|
Larché M: T cell epitope-based allergy
vaccines. Curr Top Microbiol Immunol. 352:107–119. 2011.PubMed/NCBI
|
|
59
|
Pascal M, Konstantinou GN, Masilamani M,
Lieberman J and Sampson HA: In silico prediction of Ara h 2 T cell
epitopes in peanut-allergic children. Clin Exp Allergy. 43:116–127.
2013. View Article : Google Scholar : PubMed/NCBI
|
|
60
|
Nilsson OB, Adedoyin J, Rhyner C,
Neimert-Andersson T, Grundström J, Berndt KD, Crameri R and
Grönlund H: In vitro evolution of allergy vaccine candidates, with
maintained structure, but reduced B cell and T cell activation
capacity. PLoS One. 6:e245582011. View Article : Google Scholar : PubMed/NCBI
|